State-of-the-art 3D Head Reenactment

We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.



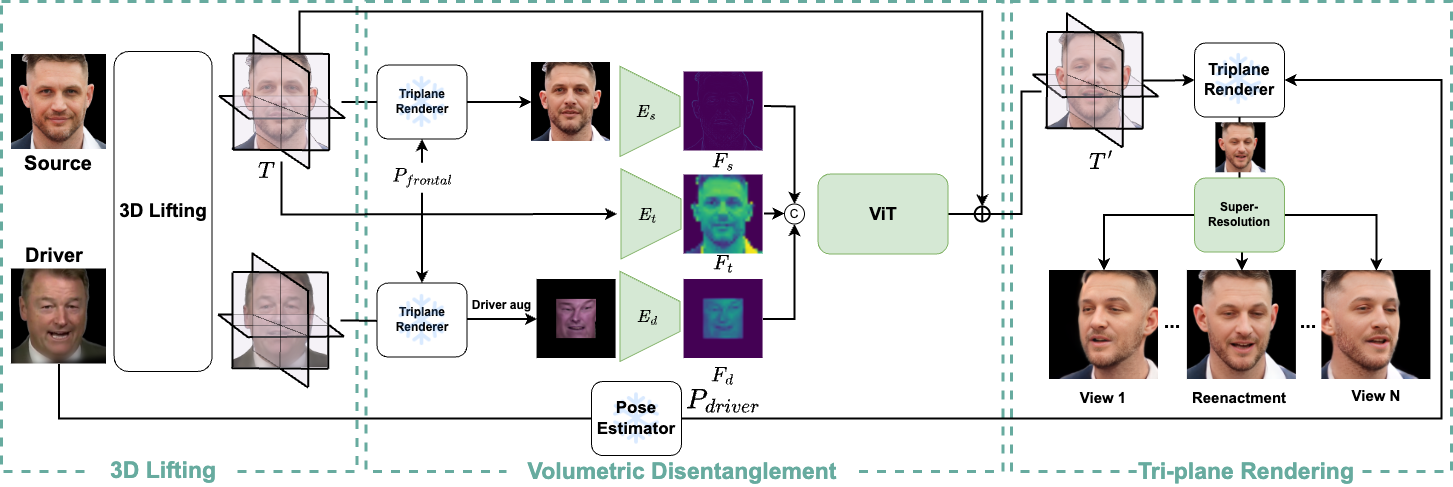
Our head reenactment pipeline consists of three stages: 1) 3D Lifting, 2) Volumetric Disentanglement, and 3) Tri-plane Rendering. Given a pair of source and driver images, we first frontalize them using a pre-trained but fine-tuned tri-plane-based 3D lifting module. This driver alignment step is crucial and allows our model to disentangle the expressions from the head pose, which prevents overfitting. Then, the frontalized faces are fed into two separate convolutional encoders to extract the face features Fs and Fd. These extracted features are concatenated with the ones extracted from the tri-planes of the source, and all are fed together into several transformer blocks to produce the expression tri-plane residual, which is added to the tri-planes of the source image. The final target image can be rendered from the new tri-planes using a pre-trained tri-plane renderer using the driver's pose.
3D Lifting. We adopt Lp3d as a 3D face-lifting module, which predicts the radiance field of any given face image in real-time. However, in our implementation, Lp3D does not work well on in-the-wild images since it was trained with synthetic data generated by EG3D. Therefore, we use a special training strategy to fine-tune it on a large-scale real-world video dataset.
Volumetric Disentanglement. We first frontalize both source and driver images and apply a strong augmentations on the frontalized driver. Then we use a hybrid ViT model to calculate the expression triplane residual which is added to the triplane of the source to transfer its expression to the target expression.
Tri-plane Rendering. We use tri-plane renderer similar to EG3D. However, we replace the super-resolution in EG3D by GFPGAN, which in our experiment produced higher quality results.
@article{tran2023voodoo,
title={VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment},
author={Tran, Phong and Zakharov, Egor and Ho, Long-Nhat and Tran, Anh Tuan and Hu, Liwen and Li, Hao},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}